Optimized repositories
JomOS adds optimized repositories automatically to improve performance and system responsiveness. These repositories also include custom kernels with various CPU schedulers and other goodies.
The optimizations used in the repositories are listed below.
Compiler optimizations
-march is the first and most important option. This instructs GCC(or other compilers) to generate code for a specific type of CPU. Different CPUs have different capabilities, support different instruction sets, and execute code in different ways. The -march flag instructs the compiler to generate specific code for the selected architecture, including all of its capabilities, features, instruction sets, quirks, and so on.
If the CPU type is unknown, or if the user is unsure which setting to use, the -march=native option can be used. When this flag is set, GCC will attempt to detect the processor and set appropriate flags for it automatically. This should not be used if you want to compile packages for different CPUs!
When compiling packages on one computer to run on another (for example, when using a fast computer to build for an older, slower machine), do not use -march=native. The term “native” indicates that the code produced will only run on that type of CPU. Applications developed with -march=native on an Intel Core CPU will not run on an old Intel Atom CPU.
These are the four x86-64 microarchitecture levels on top of the x86-64 baseline:
- x86-64: CMOV, CMPXCHG8B, FPU, FXSR, MMX, FXSR, SCE, SSE, SSE2
- x86-64-v2: (close to Nehalem) CMPXCHG16B, LAHF-SAHF, POPCNT, SSE3, SSE4.1, SSE4.2, SSSE3
- x86-64-v3: (close to Haswell) AVX, AVX2, BMI1, BMI2, F16C, FMA, LZCNT, MOVBE, XSAVE
- x86-64-v4: AVX512F, AVX512BW, AVX512CD, AVX512DQ, AVX512VL
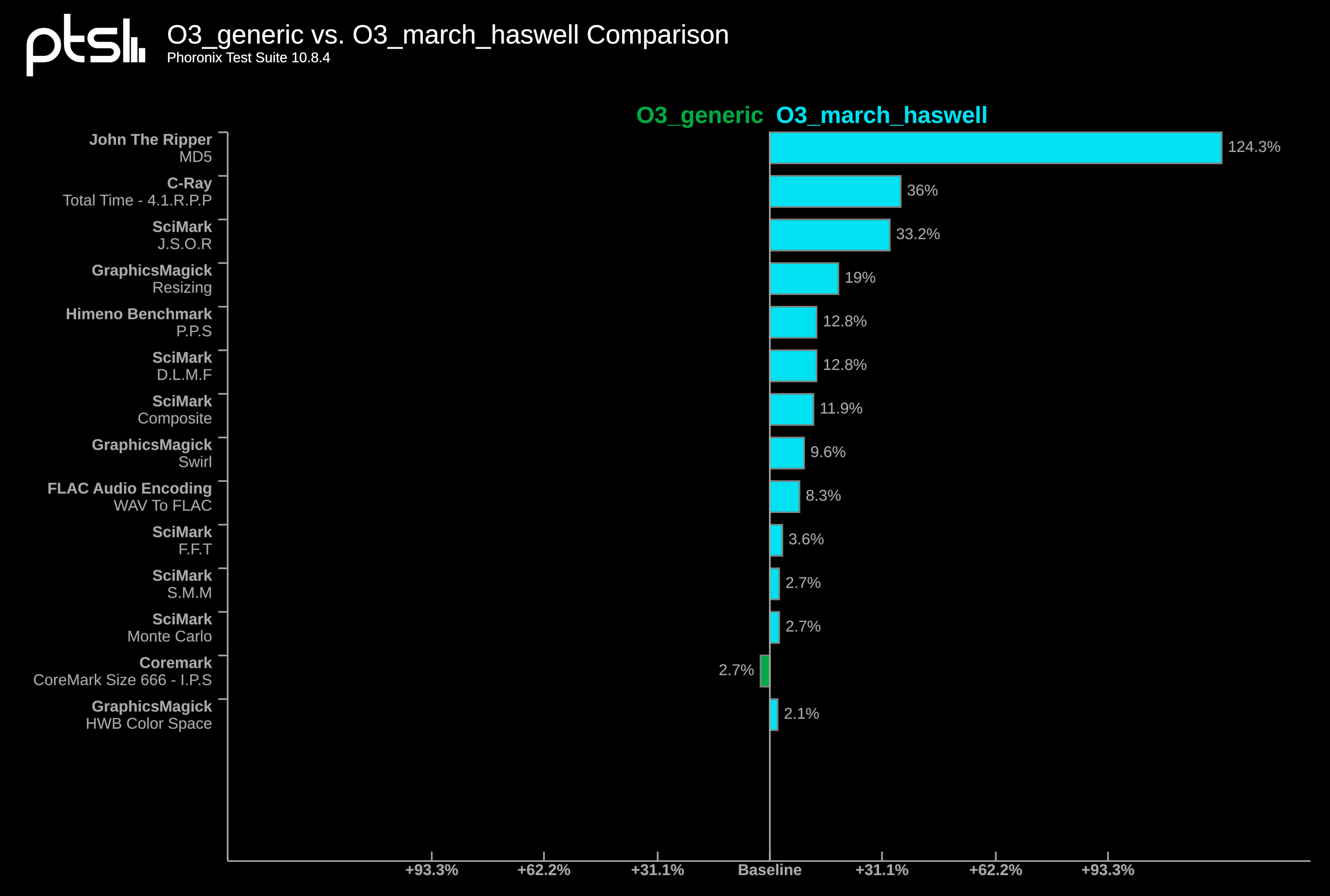
Most Linux distributions use x86-64-v2 for compatibility with older hardware, but this may limit performance on newer hardware. We detect whether your CPU supports x86-64-v3 and add repositories accordingly. The performance improvement could range from 10% to 35% depending on the processor and software used.

To check if your cpu supports x86-64-v3, you can use the following command:
/lib/ld-linux-x86-64.so.2 --help | grep "x86-64-v3 (supported, searched)"
If you get an output saying x86-64-v3 (supported, searched) then congratulations, your cpu supports x86-64-v3.
This repository is provided by CachyOS. As theres no reason to create our own v3 repositories. Many thanks to the CachyOS team for creating and maintaining this repository.
Default browser Thorium
As far as I am aware, Thorium is the fastest browser available. It also makes use of some of the compiler optimizations we use, as well as others; for more information, see Thorium.
Tuned sysctl values and other configurations
/etc/sysctl.d/99-JomOS-settings.conf
This file contains JomOS sysctl tweaks.
vm.swappiness
The swappiness sysctl parameter represents the kernel’s preference (or avoidance) of swap space. Swappiness can have a value between 0 and 100, the default value is 60.
A low value causes the kernel to avoid swapping, a higher value causes the kernel to try to use swap space. Using a low value on sufficient memory is known to improve responsiveness on many systems.
This value is automatically calculated using your ram amount
vm.vfs_cache_pressure
The value controls the tendency of the kernel to reclaim the memory which is used for caching of directory and inode objects (VFS cache).
Lowering it from the default value of 100 makes the kernel less inclined to reclaim VFS cache (do not set it to 0, this may produce out-of-memory conditions)
This value is automatically calculated using your ram amount
vm.page-cluster
refer to https://notes.xeome.dev/notes/Zram#page-cluster-values-latency-difference
vm.dirty_ratio
Contains, as a percentage of total available memory that contains free pages and reclaimable pages, the number of pages at which a process which is generating disk writes will itself start writing out dirty data (Default is 20).
vm.dirty_background_ratio
Contains, as a percentage of total available memory that contains free pages and reclaimable pages, the number of pages at which the background kernel flusher threads will start writing out dirty data (Default is 10).
Network tweaks (only for CachyOS kernels)
The BBR congestion control algorithm can help achieve higher bandwidths and lower latencies for internet traffic
TCP Fast Open is an extension to the transmission control protocol (TCP) that helps reduce network latency by enabling data to be exchanged during the sender’s initial TCP SYN. Using the value 3 instead of the default 1 allows TCP Fast Open for both incoming and outgoing connections
kernel.nmi_watchdog
Disabling NMI watchdog will speed up your boot and shutdown, because one less module is loaded. Additionally disabling watchdog timers increases performance and lowers power consumption
/etc/udev/rules.d/ioscheduler.rules
The kernel component that determines the order in which block I/O operations are submitted to storage devices is the input/output (I/O) scheduler.The goal of the I/O scheduler is to optimize how these can deal with read requests, it is useful to review some specifications of the two main drive types:
-
An HDD has spinning disks and a physical head that moves to the required location. As a result, random latency is quite high, ranging between 3 and 12ms (depending on whether it is a high-end server drive or a laptop drive bypassing the disk controller write buffer), whereas sequential access provides significantly higher throughput. The average HDD throughput is approximately 200 I/O operations per second (IOPS).
-
An SSD does not have moving parts, random access is as fast as sequential one, typically under 0.1ms, and it can handle multiple concurrent requests. The typical SSD throughput is greater than 10,000 IOPS, which is more than needed in common workload situations.
Thousands of IOPS can be generated if multiple processes make I/O requests to different storage parts, whereas a typical HDD can only handle about 200 IOPS. There is a queue of requests that must wait for storage access. This is where I/O schedulers can help with optimization.
The best scheduler to use is determined by both the device and the specific nature of the workload. Furthermore, throughput in MB/s is not the only measure of performance: deadlines or fairness reduce overall throughput while improving system responsiveness.
# set scheduler for NVMe
ACTION=="add|change", KERNEL=="nvme[0-9]n[0-9]", ATTR{queue/scheduler}="none"
# set scheduler for SSD and eMMC
ACTION=="add|change", KERNEL=="sd[a-z]*|mmcblk[0-9]*", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="mq-deadline"
# set scheduler for rotating disks
ACTION=="add|change", KERNEL=="sd[a-z]*", ATTR{queue/rotational}=="1", ATTR{queue/scheduler}="bfq"For example the udev rule above sets the scheduler to none for NVMe, mq-deadline for SSD/eMMC, and bfq for rotational drives:
/etc/mkinitcpio.conf
Base and udev replaced with systemd for faster boots and set compression algorithm to zstd and compression level to 2 because compression ratio increase isn’t worth the increased boot time.
/etc/systemd/zram-generator.conf
Use zstd compression by default, for more information visit Zram
Sources
Benchmarks
https://lists.archlinux.org/pipermail/arch-general/2021-March/048739.html
https://openbenchmarking.org/result/2103142-HA-UARCHLEVE55&rmm=O1_generic%2CO3_march_nehalem